OK, so yesterday I posted an article about how standards should be followed and the dire consequences for everyone if they aren't. OK, OK, it wasn't really that dark, but the point just being that I got on my little soap box yesterday and went off on a little rant after solving a problem that had me stymied for two and a half days with no help from the internet, StackExchange or my MVP cadre. I was frustrated. Of course, after posting the article, I get texts from my friends and colleagues saying "Hey C, nice rant, but you didn't really provide a clear answer to the problem in your post."
After re-reading my post, I have to agree. So I whipped the code from my Quix toolbox into a quick Gist that will hopefully save someone else the frustration in the future. 😎
The code is pretty self explanatory.
All you have to do to incorporate this into your own C# program is to include it in your project and then call the getInfoPathAttachments() method while passing it two arguments.
The first is the XML document constituting the InfoPath form's XML which is easily loaded to the standard System.Xml.XmlDocument object.
The second is the node path where the attachments are located in your form. In my case, the control was called "Attachment" and was literally hanging straight off the root of the document so my node path was "/my:myFields/my:Attachment".
The method will return a list of MemoryStream objects which you can then process any way you like such as saving to disk or processing further etc.
Happy coding.
C
13 December 2018
12 December 2018
When standards aren't... aka how do I deal with multiple file attachments in InfoPath
As we all know, Microsoft has been proclaiming InfoPath to be "dead" for many years now, but it's not until recently with PowerApps that we've seen any glimmer of hope for a replacement. As such, InfoPath lives on and gets migrated from one version of SharePoint to the next version after version after version...
The decoder class that follows is the same except in reverse, taking in the base64, ASCII data and then converting it into a byte array in a memory stream in lines 25/26. A BinaryReader() then reads the memory stream to decode the attachment.
They never delve into dealing with multiple attachments at any point. In fact the reference to the attachments in XML is very small and always worked from a view of single file attachments as can be seen in the code to save the attachment thus:
As can be seen from line 8, the use of the SelectSingleNode() method assumes only one file attachment. So this helped me understand the magic behind how the documents are encoded and stored in the XML of the InfoPath document, but it still wasn't giving me any glimpses into dealing with multiple attachments. Further searching brought me to the BizSupportOnline.net site and in particular their "Top 10 questions about InfoPath attachments" article. Eureka! I thought. This has to be it. They had multiple questions with answers and links to videos that would hold the key information I sought... except... their video links were all dead. 😡
My heart sank to new lows as my struggle entered day two. I stumbled upon this article from Kunaal Kapoor titled "Getting InfoPath attachments from a submitted form" wherein he explains how it could be done using the XSD Visual Studio tool to build classes off the InfoPath template. This seemed like a major departure from my current implementation, but desperate times you know...
So I tried it and as I suspected, it didn't work. OK, back to my former path. I know it's in there in the XML, I just have to find it.
OK, back to basics. Rule #1 of debugging. NEVER ASSUME ANYTHING!
So let's check, double check and triple check all our bases again.
Let's look at the attachment definition in the form.

OK, it's a simple field control, of type Picture or File Attachment (base64) with the Repeating option checked. Nothing out of the ordinary here.
Next I decided to compare the character by character, line by line results of the files. Time for my beloved Beyond Compare! If you don't have this tool in your toolbox, you're seriously missing out on productivity. The folks at Scooter Software does an awesome job with this gem of a tool. A definite must have for every geek.
As I did my comparison and got to the end of the first attachment, this is what I noticed:

On the left is the original source file that had 3 attachments. On the right is the processed result with just one. Obvious right? So then the question is... why do we only see one Attachment node in the code during processing. The answer is based on the presupposition that repeating data represented in standard XML is represented in a collection node thus:
<xml>
<LastName/>
<Attachment>
<File Name="abc.doc"/>
<File Name="xyz.doc"/>
<File Name="ugh.doc"/>
</Attachment>
</xml>
Instead, the way InfoPath chose to represent multiple attachments in this case was as follows:
<xml>
<LastName/>
<Attachment Name="abc.doc"/>
<Attachment Name="xyz.doc"/>
<Attachment Name="ugh.doc"/>
</xml>
As a result, when my code was processing the childnodes of the XML document, looking for a match against the schema in order to rebuild the new target document, it found the first Attachment node and was satisfied and then moved on. If the attachment was represented in a standards based collective node, all the files would have been caught.
It just goes to show you. Rule #1 is so true. Never assume anything. Not even when the source is a large, reputable, multi-billion dollar company. 😎
<EDIT>
If you'd like to leverage the code I wrote to solve this, I posted a follow on article the following day that can be found here:
http://blog.cjvandyk.com/2018/12/get-infopath-attachments-open-source.html
</EDIT>
Happy coding
C
One of the things that made InfoPath special was the ability for users and designers to tinker with the template and move stuff around, add and remove fields etc. and it would maintain all historic schemas in SharePoint so that any older content that was created with said schema, could be opened with the appropriate schema when needed.
Enter migration time. Queue the dramatic music please.
All migration tools, that's right, every single last one of them, when migrating InfoPath libraries, will only migrate the latest .xsn schema which of course means that ALL forms created with older schemas is now broken! This stems from the fact that migration tools use the API's provided by Microsoft and the fact that the APIs do not provide access to older schemas.
Being the industrious little problem solver that I am, I wrote my own tool to work around this problem. The tool simply downloads the latest .xsn from the target library, extracts the template.xml and manifest.xsf for parsing and then iterates the schema node by node while seeking matching nodes in the original source XML data and reconstructing the new target XML on the fly. Upon completion the new XML document is upload to the target and it fully usable as is. This works GREAT!
Then we encountered multiple file attachments.
Now I don't know if you've even ventured down the rabbit hole that is InfoPath File Attachments, but let me tell you... it's a mess! What little information is available on the web is old, outdated and hardly applicable. Oh and did I mentioned nobody and I mean NOBODY talks about dealing with MULTIPLE FILE ATTACHMENTS!!!
The first glimpses of hope I could gleam from scouring the internet was this Microsoft support article titled "How to encode and decode a file attachment programmatically by using Visual C# in InfoPath 2003".
Right in the introduction, the article had a reference pointing to an updated version titled "How to encode and decode a file attachment programmatically by using Visual C# in InfoPath 2010 or in InfoPath 2007".
I read both to be sure. There's very little difference from a code perspective between the two, but I'll reference code from the 2010 example here.
The article first walks you through the InfoPathAttachmentEncoder() class which is pretty straight forward, but it is important to note that in line 45 they are reading the file to be attached as Unicode. In line 78 the ToBase64Transform is used to convert the unicode binary of the file on disk to text in Base64 format, that can fit in XML. Finally in line 93, the memory stream is grabbed as ASCII text and returned to the caller to be inserted to the InfoPath form as an attachment.
The decoder class that follows is the same except in reverse, taking in the base64, ASCII data and then converting it into a byte array in a memory stream in lines 25/26. A BinaryReader() then reads the memory stream to decode the attachment.
They never delve into dealing with multiple attachments at any point. In fact the reference to the attachments in XML is very small and always worked from a view of single file attachments as can be seen in the code to save the attachment thus:
As can be seen from line 8, the use of the SelectSingleNode() method assumes only one file attachment. So this helped me understand the magic behind how the documents are encoded and stored in the XML of the InfoPath document, but it still wasn't giving me any glimpses into dealing with multiple attachments. Further searching brought me to the BizSupportOnline.net site and in particular their "Top 10 questions about InfoPath attachments" article. Eureka! I thought. This has to be it. They had multiple questions with answers and links to videos that would hold the key information I sought... except... their video links were all dead. 😡
My heart sank to new lows as my struggle entered day two. I stumbled upon this article from Kunaal Kapoor titled "Getting InfoPath attachments from a submitted form" wherein he explains how it could be done using the XSD Visual Studio tool to build classes off the InfoPath template. This seemed like a major departure from my current implementation, but desperate times you know...
So I tried it and as I suspected, it didn't work. OK, back to my former path. I know it's in there in the XML, I just have to find it.
OK, back to basics. Rule #1 of debugging. NEVER ASSUME ANYTHING!
So let's check, double check and triple check all our bases again.
Let's look at the attachment definition in the form.
OK, it's a simple field control, of type Picture or File Attachment (base64) with the Repeating option checked. Nothing out of the ordinary here.
Next I decided to compare the character by character, line by line results of the files. Time for my beloved Beyond Compare! If you don't have this tool in your toolbox, you're seriously missing out on productivity. The folks at Scooter Software does an awesome job with this gem of a tool. A definite must have for every geek.
As I did my comparison and got to the end of the first attachment, this is what I noticed:

On the left is the original source file that had 3 attachments. On the right is the processed result with just one. Obvious right? So then the question is... why do we only see one Attachment node in the code during processing. The answer is based on the presupposition that repeating data represented in standard XML is represented in a collection node thus:
<xml>
<LastName/>
<Attachment>
<File Name="abc.doc"/>
<File Name="xyz.doc"/>
<File Name="ugh.doc"/>
</Attachment>
</xml>
Instead, the way InfoPath chose to represent multiple attachments in this case was as follows:
<xml>
<LastName/>
<Attachment Name="abc.doc"/>
<Attachment Name="xyz.doc"/>
<Attachment Name="ugh.doc"/>
</xml>
As a result, when my code was processing the childnodes of the XML document, looking for a match against the schema in order to rebuild the new target document, it found the first Attachment node and was satisfied and then moved on. If the attachment was represented in a standards based collective node, all the files would have been caught.
It just goes to show you. Rule #1 is so true. Never assume anything. Not even when the source is a large, reputable, multi-billion dollar company. 😎
<EDIT>
If you'd like to leverage the code I wrote to solve this, I posted a follow on article the following day that can be found here:
http://blog.cjvandyk.com/2018/12/get-infopath-attachments-open-source.html
</EDIT>
Happy coding
C
23 August 2018
How do I - Fix The Standard View of your list is being displayed because your browser does not support running ActiveX controls
After migrating a site from SharePoint 2010 you find that it doesn't display the same way in your new environment. Sure, newer versions of SharePoint is sure to display content slightly differently, but this one's different. Instead of your items scrolling nicely on page in a scrollable box, the entire page now becomes a scrollable grid.
BEFORE MIGRATION
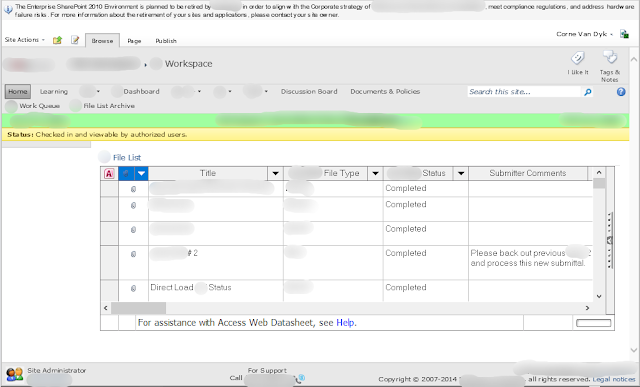
Notice the Access Web Datasheet grid displaying the content on the page.
Now take a look at the migrated content.
AFTER MIGRATION

Notice the page scroll bar to the right. The entire page is now scrolling. In addition, the error message at the very bottom of the page notes:
"The Standard View of your list is being displayed because your browser does not support running ActiveX controls."
The fix is actually pretty straight forward.
Odds are you're using Internet Explorer 11 or later and like most SharePoint sites, you'll need to tell newer versions of IE to interpret the site in Compatibility Mode. To achieve this simply:
1. Click the settings gear in the top right of IE, just below the closing X.
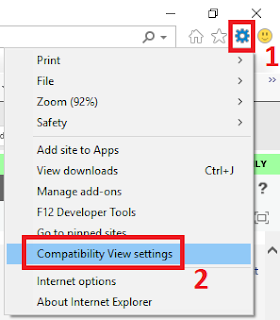
2. Click the "Compatibility View settings" option on the dropdown menu.

3. The Compatibility View Settings modal window will be displayed.
4. By default your site's root domain will be displayed in the "Add this website:" field as in #1 above.
5. Click the "Add" button (#2) in order to add the domain to the list (#3) below.
6. Click "Close".
7. The site should automatically refresh and the content should load the same way as you're used to.
Enjoy
C
BEFORE MIGRATION

Notice the Access Web Datasheet grid displaying the content on the page.
Now take a look at the migrated content.
AFTER MIGRATION

Notice the page scroll bar to the right. The entire page is now scrolling. In addition, the error message at the very bottom of the page notes:
"The Standard View of your list is being displayed because your browser does not support running ActiveX controls."
The fix is actually pretty straight forward.
Odds are you're using Internet Explorer 11 or later and like most SharePoint sites, you'll need to tell newer versions of IE to interpret the site in Compatibility Mode. To achieve this simply:
1. Click the settings gear in the top right of IE, just below the closing X.


3. The Compatibility View Settings modal window will be displayed.
4. By default your site's root domain will be displayed in the "Add this website:" field as in #1 above.
5. Click the "Add" button (#2) in order to add the domain to the list (#3) below.
6. Click "Close".
7. The site should automatically refresh and the content should load the same way as you're used to.
Enjoy
C
09 March 2018
How to improve your SharePoint performance
The speed at which SharePoint operates and
its overall performance can be greatly improved by improving the underlying data engine, i.e. SQL Server.
The Disks and the NTFS Allocation size
Initial Size
Your
SharePoint configuration and SQL Server
The overall performance of your SharePoint farm is dependent on its configuration and settings, although since SQL server is
the underlying data engine upon which SharePoint is built, the faster the information
can be written, stored and accessed, the faster the performance of SharePoint.
The Disks and the NTFS Allocation size
In order to enhance the speed of SharePoint, especially when you have a traveling demo VM, you
need the required disk size, although if your laptop’s disk size is smaller than
the required specifications, it can still be modified to enhance SharePoint performance.
This can mostly be achieved by firstly formatting the disk and then changing
the NTFS allocation size on your drives. By default, your disk reads and writes
4K at a time, however, SQL reads and writes 64K, which is far greater. Changing the allocation size in NTFS on your drive alone will
boost your performance by up to 30%.
Modifying
the Model Database to increase SharePoint performance
The SQL utilizes the information in the model
Database for creating new databases. You would think that SharePoint would use the model database, but it actually does not. As a result, when a new content database is created, by default, the auto grow settings of the database is set to 1 MB at a time and as any SQL DBA worth his salt will tell you, a SQL grow operation is by far the most expensive operation in SQL. As a result, imagine your content database being full and someone uploading a 100 MB file. That will require the content database to grow 100 times. Not good for performance at all. So always go and check your grow settings after new content databases have been added.
Initial Size
When a new database is created, it is very
important to take into consideration its initial size and the purpose of its
creation. A larger amount of space should be allotted to a new database when
they are created, in order to prevent SQL from constantly asking for more
spaces to store data. This will certainly help the overall performance of
SharePoint i.e. avoid grow operations as explained in the previous section.
Auto Growth
In the long run, when the database is filled there
will be the need for it to grow, you can specifically allocate the size you
want it to grow into. Make sure to grow the size of your SharePoint databases
by chunks that make sense in your environment. Don't forget the TempDB. Remember, every write goes through the TempDB first before it goes to your DB!
Instant File
Initialization can help speed up SharePoint but be careful
Instant file initiation allows SharePoint
to skip certain long processes during the initiation of sizing and the auto growth
processes. Talking about increasing those SharePoint Database file sizes, how
does it actually do it? Well to make sure it can be written to as it creates or
grows the database, SQL will write zeroes to validate it can write to it and
then claim it. This can be a very long process depending on the required task
SharePoint asked of SQL Server. Performing the instant file initiation will
help in saving time and increase the speed of operation. This is especially true
for demo machines, but beware that the space must be available. You do NOT want to run out of space!
Guys we're back!!!
Hi guys, thanks for bearing with us doing the restructuring of our site. You know at times it is better to take a step backward so as to be able to take three forward. Yes, we're fully back and ready to rock the show with details on SharePoint and we hope to give you the very best Tips. Once again, Thank you so much.
05 March 2018
Blog consolidation ongoing... please bear with me.
Hey everyone,
Please bear with me as we consolidate all my blog posts from various blogs together under this one source. My apologies if you see "old" content coming through your feed over the next couple weeks. This will be eventually serve to make for a better, more complete experience for all going forward.
Thanks!
C
Please bear with me as we consolidate all my blog posts from various blogs together under this one source. My apologies if you see "old" content coming through your feed over the next couple weeks. This will be eventually serve to make for a better, more complete experience for all going forward.
Thanks!
C
Subscribe to:
Posts (Atom)
-
Ever wondered what the new SharePoint Online URLs are all about? Take for example https://cjvandyk.sharepoint.us/:x:/r/sites/Site1... What ...
-
 Have you ever started creating a list view in SharePoint and because you're experimenting, you chose to make it a "Private" vi...
Have you ever started creating a list view in SharePoint and because you're experimenting, you chose to make it a "Private" vi... -
http://blog.cjvandyk.com/p/list-of-downloadable-prime-numbers.html